






Fortune 100 response to DE&I pressures

Data masking is the process of hiding original data with modified content. Actual data is hidden by random characters to protect sensitive data from third parties. In this article, we will take a look at the challenges associated with implementing data masking and the opportunities that it presents.

The objective of Data Masking is to protect sensitive data such as personally identifiable information (PII), protected health information (PHI), payment card information (PCI-DSS), or commercially sensitive intellectual property data from those who don’t have permission to view it. In doing so, the data must remain usable. It is more common to have masking applied to data that is represented outside of a corporate production system. However, this practice is not always restricted to non-production environments.
Third parties can’t be trusted. Many businesses share customer data with market researchers. Sending actual personally identifiable data, payment card information, or protected health information to third parties would not only be risky because of how many people could potentially access it for misuse but also because doing so may run afoul of the compliance regulations governing different industries.
Insider threats. According to a 2016 study, more than 25 percent of all data breaches involve employee negligence. Whether through maliciousness or carelessness, the legitimate data access privileges of employees contribute to many data breaches and leak incidents. This threat can be minimized by allowing each employee to see only the data they require to complete their work with the remaining data masked.
Many business operations don’t need real data. Plenty of organizations require data in order to build and test new programs or functions, as well as to test necessary patches and upgrades. It would be impossible to tell if a program is going to perform as it needs to if it can’t be tested with data. However, if it were tested with the actual data of users, customers, or employees, it would open up that data to the eyes of all kinds of employees or contractors who don’t require access to it. It would also allow that data to be stored in potentially insecure development environments that may be vulnerable to hackers.
Regulatory Requirements. The EU regulates how any organization storing or processing the data of any person in the EU can handle that data. Among many other requirements, the General Data Protection Regulation (GDPR) specifically mentions in Article 32 that data masking be used to pseudonymize sensitive data to help protect EU citizens from data breaches and other unauthorized access. Considering that failing to abide by the GDPR can result in everything from a written warning to a fine of 20 million EUR, it’s in an organization’s best interest to comply. Other applicable APAC regulations requiring Data Masking for the use of sensitive production data in non-production environment are Japan (PPI, Chapter IV, Section 2, Article 36), Australia (Privacy Act 1988), Singapore (PDPA, section 25), Malaysia (Personal Data Protection Code of Practice 3.6), Korea (PIPA Article 3) amongst others.

Given the diverse nature of different business, there is definitely no ‘one size fits all’ strategy that can be adopted. We can rather adapt the following approach to suit specific needs of the organizations. As a business requirement, sensitive production data in structured form (database) is often required to be used in non-production environments (considered to be less secure). The following workflow helps in establishing a step-by-step process to implement secure data masking for structured data.
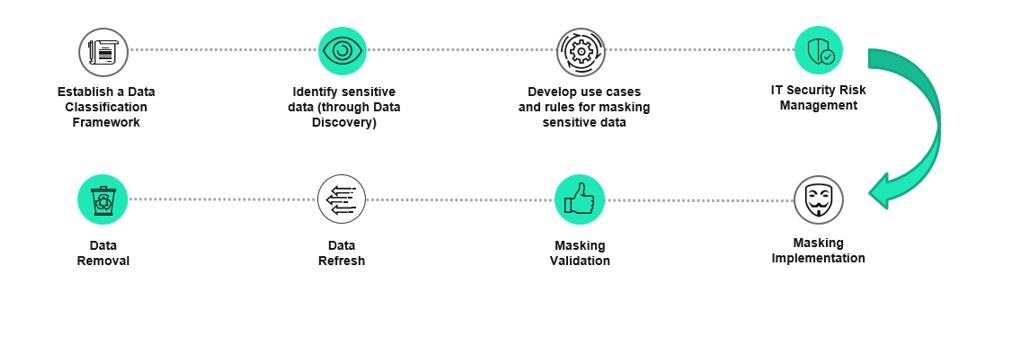
1. Establish a Data Classification Framework – Includes data classification policies, objectives, workflows, classification scheme and data owners. Data classification helps you prioritize your data protection efforts to improve data security and regulatory compliance. It also improves user productivity and decision-making, and reduces costs. Data is often classified as public, confidential, sensitive, or personal
2. Identify sensitive data (through Data Discovery) – For each of the data sets that support business processes, apply labels by tagging data. This can be done manually or by using automated solutions.
3. Develop use cases and rules for masking sensitive data - In alignment with the business processes and the specific data classification framework, understand where the sensitive data is, who needs access to and how do you want to mask it based on different scenarios (use of production data in a non-production environment, cross border data transfers, etc). The use cases should look at combinations of non-sensitive data that could possibly become a sensitive data identifier.
4. IT Security Risk Management – Adopt a mature IT Security Risk Management practice to handle the overall data masking process by documenting the sensitive data mitigation strategy, request approvals, sign-offs from data-owners business owners and security risk officers (for risk exceptions), onward data transfers and deletions after expiry for untreated sensitive data in unsecure environments. To evaluate the effectiveness of sensitive data mitigation strategy, here are some of the factors that can be taken into consideration.
If untreated sensitive production data is transferred to a non-production environment, it is essential to perform a gap analysis of the security controls in a non-production environment. Some of the security controls that can be considered are
5. Masking Implementation – For requests involving production data transfer, masking should happen in secure production like environment before transfer to less secure non-production environments.
Masking Process Flow
a. Review the masking
b. Prepare masking script aligned to the strategy
c. Enforce access & version controls on the masking scripts
d. Test the masking script against requirements
Masking can be done manually following the above procedures or by adopting Enterprise Data Masking tools that support automated Data Masking and predefined masking rules to ease of use.
6. Masking Validation – Upon successful masking implementation, it has to be validated against the requirements laid out in the masking strategy. Ideally, the data owner does the formal validation and provides sign-off for using it.
7. Data Refresh – Once the masking script/job is set up, it can be executed multiple times (in a controlled manner) to perform data refresh. Some of the controls to consider are
8. Data Removal – After determining that the data refresh from production to non-production environment is no longer required, the existing (treated or untreated) sensitive data should be wiped out from the non-production environment.
There are multiple ways to implement data masking, depending upon requirements. For example: if you need to mask the ‘Date of Birth’ field then you could simply randomize the data. However, if your application needs to be able to recognize that this is indeed ‘Date of Birth’ then you will need to ensure that the randomization creates the right format or, indeed, that it generates the ‘Date of Birth’. Wherever you mask the same data in different places you may need to be able to ensure that the same result is produced in both cases and, going still further, you may need to be able to ensure referential integrity during the masking process. Thus, multiple ways to mask the data are needed to suit different scenarios.
Picking the right masking solution
There are multiple tools available for Data Masking technology. Since data masking is not a standalone control, businesses need to first classify the sensitive data and then discover where it resides. There are various independent tools for each of these functionalities and can be used together in conjunction to fulfill security requirements. However, the trend is likely to be towards vendors providing integrated capabilities that do all of these things. The synergies between data masking and test data management have paved the way to the emergence of suites of tools that have a data focus for application development and testing, to complement traditional tools that have a more application focus.
Here are some of the features and capabilities to look out for in a data masking tool.
At Sia Partners, we have a wide range of business consultants and data security professionals to help clients meet their business objectives for Data Masking and other topics like Data Discovery and Data Classification. We do a study on your business landscape and data management process, perform data security gap analysis, propose and implement data security solutions tailored to your business needs.


