Sustainability Management: From ambition to impact

Insurers are not immune to the increase in cases of fraud observed in all sectors of the economy. Faced with increasingly imaginative policyholders to create fraud scenarios and the emergence of organised fraud, insurers must equip themselves to fight this scourge. This dossier aims to explain the c

Insurers are not immune to the increase in cases of fraud observed in all sectors of the economy (fraud in health insurance, taxes, SNCF travel, etc.). In 2013, according to ALFA (Agence pour la Lutte contre la Fraude en Assurance), French insurance (in damage) detected 44,814 acts of fraud, for a recovered amount of 214 million euros. Fraud refers to deliberate acts or omissions with the intent to mislead the insurer to obtain a financial benefit. The ways to defraud are as follows:
- cheating at subscription to pay less;
- cheating in a claim to get more benefits;
- simulate a disaster to make money.
Faced with increasingly imaginative policyholders to create fraud scenarios and the emergence of organised fraud, insurers must equip themselves to fight this scourge. In 2014, French insurers are estimated to have spent €20 million on the deployment of anti-fraud measures, while 81% of insurers use automated detection techniques.
This dossier aims to explain the challenges of combating fraud and the technical means implemented by insurers. Indeed, in the event of fraud, the insurance code provides for sanctions against the insured which have a direct impact on the insurer's claims / premium ratio. It is then up to the insurers to provide their fraud team with the solution most relevant to their constraints (operating cost of the solution, desired performance, fraud history and available data,...).
Fraud can be detected as soon as the contract is subscribed, in particular by checks at AGIRA. AGIRA's databases provide insurers with the history of contracts terminated either by the insured or by the insurer. For example, an insured who purchases an auto policy while terminated by a competing insurer may have his or her benefits forfeited and his or her policy void.
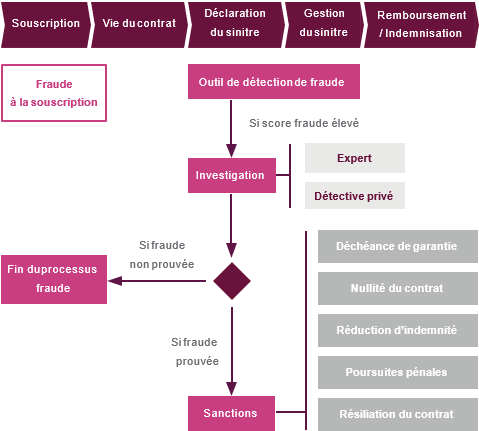
It is precisely when the claim declaration is made that fraud is detected in the majority of cases: solutions make it possible to automatically give a fraud score to each declared claim, before a manual investigation by the managers of the fraud team. If necessary, the fraud team can call on experts or even private detectives. If fraud is proven, specific sanctions are provided for according to the seriousness of the damage:
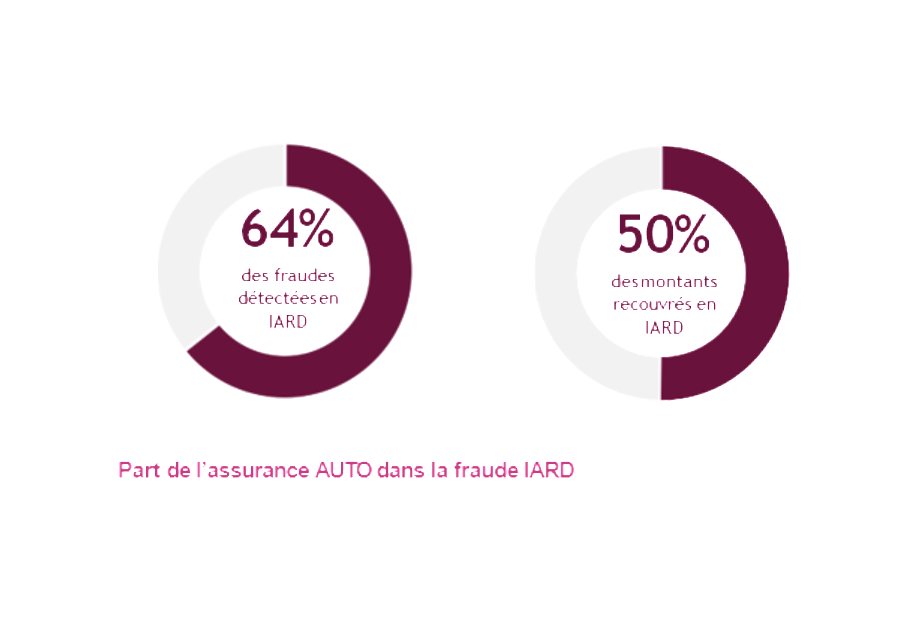
With 27,000 frauds detected and €110 million recovered, automobile insurance concentrates the majority of identified fraudulent acts on property and casualty activities. This fraud would represent more than 1 billion euros per year or 5 points of gross margin for AUTO insurance.
Fraud is a particularly significant issue given that the AUTO market is subject to strong pressures in terms of profitability and competition. Indeed, the combined ratio of this activity has remained above 100% since 2005. In addition, the introduction of infra-annual termination by the HAMON law, as well as the growing importance of Internet comparators in the customer experience, have made this market very competitive. Each point of profitability gained or lost, therefore, presents a highly strategic challenge.
These figures correspond to estimates at the level of the French market. Statistical studies on fraud show that some customer profiles present a significantly higher than average risk. The impact of fraud could thus significantly exceed 5 margin points in these high-risk segments.
AUTO insurance offers a wide variety of frauds, which can be explained by:
AUTO insurance fraud is mainly committed by individuals seeking a one-time profit in a purely opportunistic approach. However, this fraud may be the result of organised gangs that exploit legal or contractual loopholes or even shortcomings in insurers' control procedures.
This scenario has occurred to Canadian insurers who have been victims of an estimated $1 billion in sophisticated fraud. Fraud rings bought a luxury car, recruited fake passengers and then caused a minor collision with a normal motorist. The latter's insurer was then asked to pay compensation for alleged material and, above all, physical damage. The fraudsters reported multiple injuries and traumas on the basis of false medical certificates and false health care bills. This fraud was only possible because of a weakness in the Canadian insurance system that compensates third parties for damages without seeking to establish liability. Insurers have also been blamed for their laxity in dealing with the risk of fraud. The latter considered that it was cheaper to pay undue compensation than to initiate investigations. This example illustrates the importance of mechanisms to minimize moral hazard through legislation, contractual clauses and control procedures.
AUTOMATIC FRAUD DETECTION: AN OPERATIONAL NECESSITY
In 2014, more than 8 million AUTO claims were compensated, including approximately 27,000 identified fraudulent cases, representing a frequency of 0.3%. However, this rate appears to be greatly underestimated since it only concerns fraud detected by insurers. The actual proportion of fraud can be estimated at a few percent in AUTO insurance.
In addition to this low frequency, fraudulent cases often have characteristics that are relatively similar to non-fraudulent cases. There is no specific variable or rule to characterize fraud cases in a simple and robust way.
Schematically, fraud detection consists of looking for a yellow pin in a straw bale. From a technical point of view, this means tracking down the weak signals that characterize fraud.
In this fight, claims managers are in the front line. The latter can report suspicious cases in order to initiate investigations. This identification is based on the experience acquired in the analysis of the elements of the claim, but also on the feeling of the exchange with the insured. This human aspect is a specific feature of managers that cannot be reproduced in fraud detection models.
Nevertheless, an insurer covering 100,000 contracts must deal with an average of 20,000 cases per year with a team of about ten managers. The latter cannot carry out an in-depth analysis of each claim without risking compromising the fluidity of the entire management. Moreover, fraud is too complex a phenomenon to be fully understood by a manager, however experienced and psychologist he may be.
The use of automatic detection models is therefore an operational necessity to effectively combat fraud. These models are based on 3 distinct approaches:

This approach consists in defining a corpus of binary rules each characterizing a suspicious situation. A claim checking one of these rules is considered potentially fraudulent and will therefore have to be checked or even thoroughly investigated.
The rules adopted generally reflect a formalization of a certain "common sense" and managers' experience in fraud matters. Some quantitative rules can be calibrated on the basis of statistical analyses (e.g. frequency threshold or atypical cost). However, this quantitative aspect remains limited to a simple univariate statistical analysis.
As the types of fraud are intrinsically linked to the guarantee in question, the decision rules are generally defined at the level of each guarantee. The place models retain between 10 to 20 rules per guarantee, which ultimately results in a corpus of about a hundred rules.
The main advantage of this type of model is its operational simplicity. Indeed, the implementation of such an approach does not require any specific database or complex modelling work. The notion of binary rule is also intelligible to all the actors involved, who can thus participate in the construction of the model, implement it and make it evolve.
However, binary decision rules appear too rudimentary to capture the complexity of the fraud phenomenon. This deficiency can lead to a model with very low specificity that will produce many false positives. A high proportion of cases identified as suspicious, although in reality not fraudulent, can make the results unusable with a too wide scope of claims to investigate. The investigation costs may then be higher overall than the amount of fraud to be recovered. A selection of sufficiently restrictive rules, however, makes it possible to reduce this risk.
This approach is probably the best compromise between performance and operational cost. Its summary nature necessarily limits its detection performance in complex cases of fraud. Nevertheless, this type of model makes it possible to define a first scope of investigation targeted on the most at-risk cases. In the end, although not sufficient in itself, this decision rule approach is an essential first step for any insurer wishing to set up an automatic fraud detection system. This type of model is implemented by a majority of market players.

This approach aims to build a statistical learning model to predict the classification of reported claims in one of the following 2 classes:

This classification model makes it possible to estimate the probability of belonging to the "fraudulent claim" class, noted at Yˆ, of the i claim i in relation to a set of explanatory variables X j :
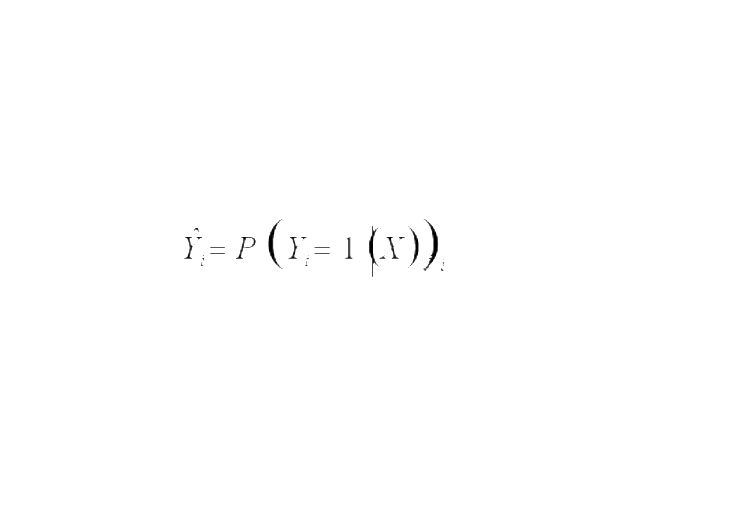
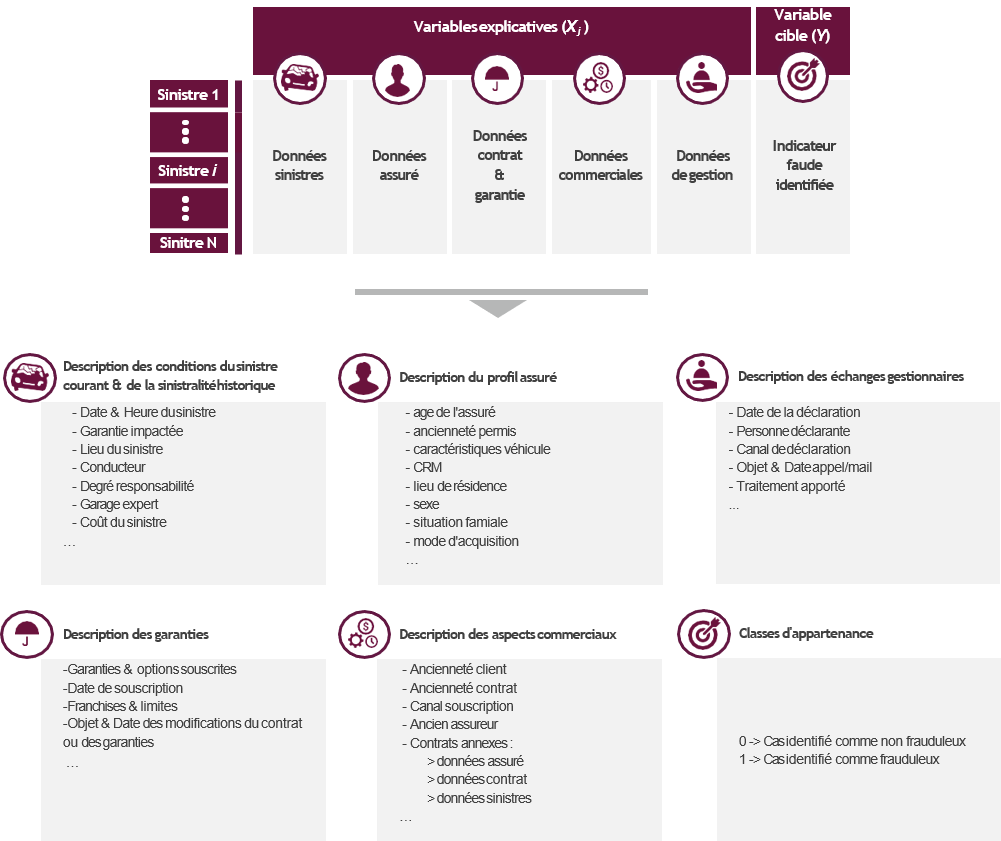
The model is calibrated from a fraud database that contains for each claim the historical scope used:
The complexity of the fraud phenomenon requires to consider many explanatory variables from different sources (claim base, insured base, commercial base, ...). The creation of this database is the main operational constraint of the approach. Indeed, the identification of the class of claims requires a history of detected fraud. The supervised approach can therefore only be envisaged on the basis of a pre-existing anti-fraud mechanism.
The supervised approach aims to solve a classification problem. The approach to be implemented therefore follows the one applied by the pricing services in the context of transformation, retention or propensity models:

However, fraud modelling has two specific features that have a significant impact on the operational process:
The supervised approach ultimately makes it possible to build an automatic fraud detection model that takes into account the complexity of the phenomenon on the one hand, and is based on objective bases on the other. The use of machine learning algorithms makes it possible to capture the complexity of data using a "data driven" approach.
The "black box" aspect of these models is often a cause for disqualification when a certain traceability is required. However, in a fraud detection context, the need for traceability appears less significant, which makes it possible to consider this type of algorithm.
The Achilles' heel of the approach is at the level of the fraud base. Indeed, the model learns to identify the detected frauds that are submitted to it via the learning database. A type of fraud that has never been detected by the entity cannot be identified by the model because it will never have learned of it. The predictive capacity of the model is therefore conditioned by the quality of the pre-existing fraud identification system on which the learning base is based. As a reminder, AUTO insurance fraud is estimated to represent more than 1 billion euros for only 110 million euros recovered. This gap illustrates the limits of the supervised approach, which is nevertheless an essential part of the anti-fraud system.
This approach aims to develop a statistical learning model to group the data into different homogeneous classes not known a priori. The model will analyze the data structure and classify the observations according to their degree of similarity. The objective is no longer to determine rules for predicting classification into a target class, but to identify grouping rules within different classes defined by the model itself. Schematically, the unsupervised approach is to let the model analyze the data without specifying what it needs to find.
This approach makes it possible to identify observations with an atypical structure within a database. By assuming that a claim with atypical characteristics potentially conceals fraud, this approach can be applied in a context of automatic fraud detection.
The model learns from a database similar to that of the supervised approach but limited to explanatory variables only. The absence of a target variable has 2 major advantages:
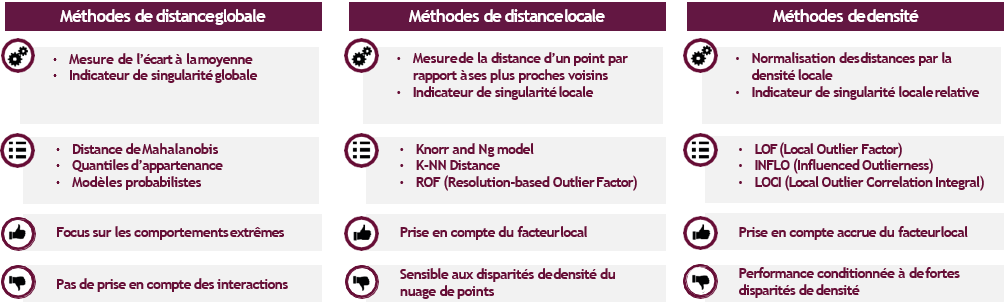
The unsupervised models are all based on the same principle : a measure of the singularity of each observation. This measurement can correspond to a distance or density, estimated locally or globally, depending on the model considered. The unsupervised algorithms are divided into 3 main families:
The absence of a target variable implies that there is no parameter setting, variable selection or model validation phase. This specificity has the advantage of operational simplicity. Nevertheless, the lack of feedback on the quality of results can sometimes be confusing. The user is reduced to placing blind trust in his model.
This disadvantage can be mitigated by 2 methods:
The unsupervised approach still appears to be little considered by insurers in the context of fraud detection. However, the latter has clear advantages, starting with its lack of prerequisites for immediate implementation, as well as its ability to identify types of fraud that have not yet been detected. Nevertheless, the assumption underlying the approach, which links fraudulent and atypical characters, may prove to be inaccurate. The impossibility of configuring and validating the model does not allow to confirm this fundamental hypothesis. The risk is therefore to initiate costly investigations into cases considered atypical by the model, although in reality not fraudulent. This flaw leads us to consider the unsupervised approach as a simple complement to the supervised approach
DETECT FRAUD BY ANALYZING SOCIAL NETWORKS
By 2014, two-thirds of insurers had improved their fraud detection systems, with an average increase of 3% in the number of cases identified. This modest performance illustrates the complexity of detecting fraudulent cases. The insurer has only limited data that do not concern the behaviour or lifestyle of its policyholders. This information, which is particularly relevant to identifying fraud, has never been so available, collected and exploitable via social networks.
The analysis of social networks10 to combat fraud is widely cited as a case study in the Big Data literature. However, the current operation of these networks is limited to a manual and ex-post analysis of suspect profiles. The transition to industrial exploitation is a major challenge for future anti-fraud measures.
If the GAFAs (Google, Amazon, Facebook, Apple) know their users well enough to predict their behaviour, what about insurers? What data is relevant to detect fraud? What information is really available on social networks?
As soon as we take an interest in personal data, Facebook is an essential source of information. The public data of its users are already used by insurers in other countries to prove certain cases of fraud:
Beyond the analysis of content published by an insured, data about the network of friends can be valuable in AUTO CR fraud. Indeed, the analysis of the links between the individuals involved in an accident makes it possible to know whether they know each other. A high degree of proximity implies a high risk of reporting fraud, as the policyholders have potentially agreed to change the context or consequences of the accident.
Access to Facebook data and services is provided through an API. A developer can use the Facebook API to request public data (events, participants, fan pages, etc.) or personal data. However, the collection of personal data requires a connection with the user, which requires the creation of an application, website or registration system linked to Facebook.
The number two car insurance company in the United States (GEICO) requires registration on its website via Facebook, which allows it to collect data on all its customers. However, this approach implies a total dependence on Facebook, which is the only one to decide on the terms of use and the data available via its API. Dozens of startups experienced this bitterly last year when Facebook decided to no longer make the list of friends of public accounts available. The new API rules no longer allow you to retrieve all of an insured's friends, but only those who are also using the application.
This example illustrates the risk of dependency induced by the use of the API provided by Facebook, which can unilaterally "turn off the tap" at any time. This risk is not specific to Facebook but concerns any API whose rules are defined exclusively by the source company. Insurers must therefore be aware of this risk before initiating developments involving the use of an API.
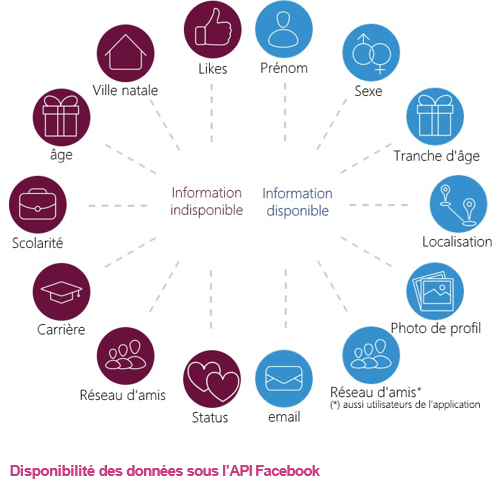
Facebook user data is very relevant to the fight against fraud. The automatic analysis of content published by a customer (on sick leave but posting holiday photos at the beach) remains to this day at the experimental stage and requires the use of specific analysis tools (text mining/image analysis). But other data such as the network of friends can already be used for industrial purposes.
Access to this data presents a real cost of entry without any guarantee on the durability of the solutions developed. As a last resort, a collection of information by web scraping would make it possible to free oneself from the constraints of the API at the cost of increased technicality.
The main obstacle to the use of social networks may ultimately not be technical but legal. A massive collection of personal information would indeed contradict some of the key principles of the CNIL12:
to be able to access, contest or rectify the data collected.
Despite a certain potential, the exploitation of social networks within fraud detection models cannot be considered until this legal mortgage has been lifted.
If you want to know more about our AI solutions, check out our Heka website: https://heka.sia-partners.com/
Contact : david.martineau@sia-partners.com

