The Next Layer of Marketing Measurement: Agentic…

What is the key to test and measure the effectiveness of your Sanctions Screening system?

Eliminating any uncertainty around sanctions screening is required to protect national security interests as well as to evade hefty sanctions fines. This article will cover 6 essential areas of testing to properly assess the effectiveness of your Sanctions Screening platform. Sanctions Screening is important for many applications, such as real-time transaction filtering (mainly for Financial Institutions and Money Service Businesses), customer identification, or “KYC” (Know Your Customer), and for background checks or any type of screening where sources should be checked against a list of sanctioned names/entities.
The importance of having a precise understanding of sanctions screening systems, including the rules set and the algorithm, is frequently forgotten by users. This first step helps to ensure the accuracy of proper testing. Languages and codes should be documented and used as a guide to design your test strategy and cases.
Different filters have various levels of complexity, some include applying standard algorithms with minor changes, some include advanced treatments and rules. Indeed, when reviewing the results of your testing, it is important to be able to understand why something did hit (or did not) and adjust it as required. Below is a non-exhaustive list of items to be reviewed:
An algorithm solely based on “phonetic” similarity approaches (i.e., words sound the same - such as Metaphone) may not be sufficient to detect typographical errors.
A transaction including “MIAMI, FLORIDA”, might create a hit against the name “FLORIDA” which is a city in CUBA, and a Good Guy could be created for that “MIAMI, FLORIDA” against “FLORIDA”.
Stop words (or common words/stems) such as “THE”, “ABOUT”, “OF”, “LTD” are commonly ignored in screening as they do not bring value in matching sanctioned entities and might create false positives.
In the example above, “FLORIDA” could be equivalent to “FL” (that would have created a hit in the example above).
All the above criteria should be considered when creating your testing strategy and test cases.
Most of the recent filtering systems come with Complex matching algorithms, which should be understood by the users and testing/analytics group (see item 1 - “Know Your Filter”). Users are often challenged as to how to properly perform “black-box” testing, often proprietary, with source code not available to the financial institutions.
When assessing the fuzzy matching logic of your algorithm, one should consider testing a wide spectrum of name variations, such as:
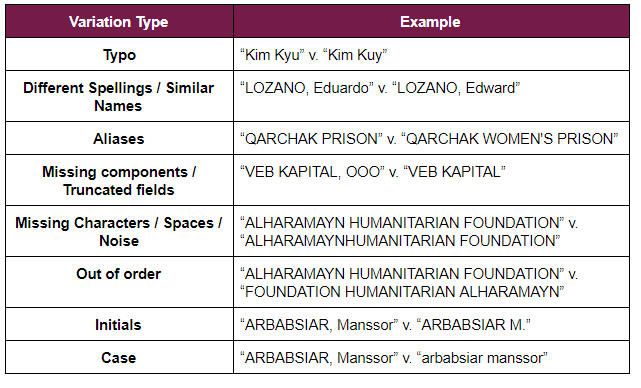
The example above was taken from the OFAC SDN list as of 06/12/2020
Examples above should be used as a baseline, but you should assess and consider all types of variation of names, entities, vessels, aircrafts relevant to your activities, and avoid reusing the same names over-and-over in your testing to avoid bias. Variations can also be chained together (e.g., case variation and then out of order), and depending on the complexity, be assigned a risk score.
Best practices suggest that for each risk-score and type of variation, a wide number of randomly generated variation should be used, in order to avoid any bias brought by the user creating the test cases.
When reviewing results, one should slice the data using different dashboards, including by risk score and by type of variation. It should be noted that all variations do not present the same risk. For example, if a first and last name are swapped, it should be considered a higher risk than if two typos are applied to one name.
Financial Institutions and regulated Money Services Businesses can use a wide array of formats when inputting information, which each can be updated regularly, and have specificities that should be known when testing a sanction filtering system.
Indeed, it is important to test the ability for a sanctions screening system to catch names with and without variation as a text entry, but also while these names are inserted in payments or messages.
The first step would be to test various names placed in all of these formats, as well as testing all relevant fields for scanning, in order to ensure that filtered fields are validated. As per the Wolfsberg Guidance, important fields to be screened include:
1. The parties involved in a transaction, including the remitter and beneficiary, Agents, intermediaries and FIs,
2. Vessels, including International Maritime Organisation (IMO) numbers, normally in Trade Finance related transactions,
3. Bank Names, Bank Identifier Code (BIC) and other routing codes,
4. Free text fields, such as payment reference information or the stated purpose of the payment in Field 72 of a SWIFT message,
5. International Securities Identification Number (ISINs) or other risk-relevant product identifiers, including those that relate to Sectoral Sanctions Identifications 8 within securities-related transactions, and
6. Trade finance documentation, including the:
In addition, more complex cases should be reviewed. A known market example would be for SWIFT messages, if the entity “GASOLINERA Y SERVICIOS VILLABONITA, S.A. DE C.V.” (49 characters long) were to appear in a Bank-to-Bank Information field (typically field 72 in a MT103), it would have to be truncated to the next line. Indeed, the 49 characters fall above the 35 characters limit of each line in a field 72 in SWIFT. In addition, after the first line, 2 characters are reserved for the “//” marked as a continuation character. The SWIFT message might look the following way :
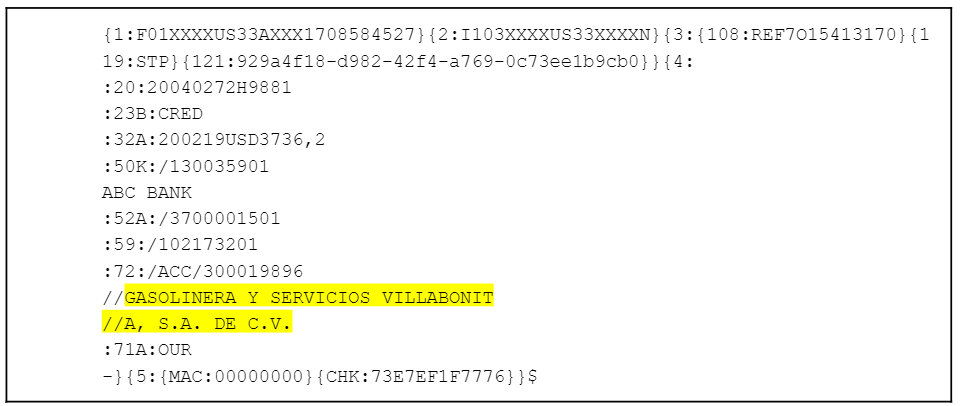
Cases with many characters need to be reviewed to ensure that full words are not split up into separate lines, as seen in the case above where “VILLABONITA” may be scanned as “VILLABONIT.”
In our experience, it is crucial to test these formats conscientiously as each have their specificities. For example, in Fedwire format, the letter “B” is inserted before the BIC code on field 5100, which might confuse some systems while scanning Fedwire raw formats.
Common formats can include SWIFT, Fedwire Funds Service (FED), Clearing House Interbank Payments System (CHIPS), SEPA, RTP, list of client names, XML, internal/proprietary formats. The configuration of each field/format should be understood as some are scanned as a “full name” or as a free text.
Each of these formats has a unique way of structuring certain data and information applicable to the transaction and should be mapped correctly to sanctions lists.
Reviews of sanctions platforms must include a check of the completeness and frequent update of the watch lists being utilized.
Indeed, in the US, OFAC operates under strict liability, which means that if a name was recently published, it is effective immediately and should be stopped as soon as the new list is updated.
Sanctions List Management is a difficult topic, and it is important to consider automation around the watch list update process, especially if manual tasks are involved and if multiple operations have to be made in order to make the list available in the system. The user should also verify the scope of lists being screened, that can be either not complete enough, or include information not relevant to the business.
Lastly, in the US it is common to include all lists published by the OFAC but also BIS and BISN depending on the transactions. Typical other lists could include Interpol, UN and EU sanctioned lists, as well as specific other geographical lists, and internal watch lists.
As discussed on item #3, all the formats being tested should be considered while also ensuring that only the important information is being screened. An ongoing review process should include a justification and test of the screening of each format and field as well as a check of the appropriate watch lists.
As an example, it is often seen that Vessels create hits against customer-to-customer transactions which will not be relevant for that type of transaction. Additionally, some systems create hits against weak aliases, which most of the time do not bring value and create a lot of false positives.
Depending on the sanctions platform being used, industry best practices should be considered, including configuration type, the screening scope the volume of false positives.
Often, vendors organize user groups and participation is important in order to understand system versions and best practices for review and testing of filters.
Both effectiveness and efficiency, in parallel, are important to tests and review. This pairing allows for a risk-based approach in order to come up with the best possible balance.
A system generating too many false positives will not only burn operational resources, but will also dramatically increase your risk of missing a sanctioned entity while a system with less effectiveness will likely miss names when slightly changed. Both these scenarios could introduce a large sanctions risk, as well as fines and regulatory scrutiny.

At Sia Partners, we have developed the Sanctions Challenger Solution which can help you automate the testing of your sanctions screening platform, feel free to reach out to us for more information

