






Observatoire international des e-fuels, édition…

Quelle est la clé pour tester et mesurer l'efficacité de votre système de filtrage des sanctions ?

Il est nécessaire d'éliminer toute incertitude quant au filtrage des sanctions afin de protéger les intérêts de sécurité nationale et d'éviter de lourdes amendes. Cet article couvre 6 domaines essentiels de tests pour évaluer correctement l'efficacité de votre plateforme de filtrage des sanctions. Le filtrage des sanctions est important pour de nombreuses applications, comme le filtrage des transactions en temps réel (principalement pour les institutions financières et les entreprises de services monétaires), l'identification des clients, ou "KYC" (Know Your Customer), et pour les vérifications d'antécédents ou tout type de filtrage où les sources doivent être vérifiées par rapport à une liste de noms/entités sanctionnés.
Les utilisateurs oublient souvent qu'il est important de bien comprendre les systèmes de filtrage des sanctions, y compris les règles établies et l'algorithme. Cette première étape contribue à garantir l'exactitude des tests appropriés. Les langues et les codes doivent être documentés et utilisés comme guide pour concevoir votre stratégie de test et vos cas.
Les différents filtres ont différents niveaux de complexité, certains comprennent l'application d'algorithmes standard avec des modifications mineures, d'autres comprennent des traitements et des réglages avancés. En effet, lorsque vous examinez les résultats de vos tests, il est important de pouvoir comprendre pourquoi quelque chose a fonctionné (ou non) et de l'ajuster en conséquence. Vous trouverez ci-dessous une liste non exhaustive des éléments à examiner :
Un algorithme basé uniquement sur des approches de similarité "phonétique" (c'est-à-dire que les mots se ressemblent) peut ne pas être suffisant pour détecter les erreurs typographiques.
Une transaction incluant "MIAMI, FLORIDA", pourrait créer un hit contre le nom "FLORIDA" qui est une ville de CUBA, et un Good Guy pourrait être créé pour ce "MIAMI, FLORIDA" contre "FLORIDA".
Les mots d'arrêt (ou les mots/articles courants) tels que "le", "à propos de", "de" sont généralement ignorés lors du filtrage car ils n'apportent rien aux entités sanctionnées correspondantes et peuvent créer de faux positifs.
Dans l'exemple ci-dessus, "FLORIDA" pourrait être équivalent à "FL" (ce qui aurait créé un hit dans l'exemple ci-dessus).
Tous les critères ci-dessus doivent être pris en compte lors de l'élaboration de votre stratégie de test et de vos cas types.
La plupart des systèmes de filtrage récents sont dotés d'algorithmes de correspondance complexes, qui doivent être compris par les utilisateurs et le groupe de test/analyse. Les utilisateurs sont souvent mis au défi de savoir comment effectuer correctement des tests "boîte noire", souvent propriétaires, avec un code source non disponible pour les institutions financières.
Lors de l'évaluation de la logique de matching floue de votre algorithme, il convient d'envisager de tester un large éventail de variations de noms, telles que :
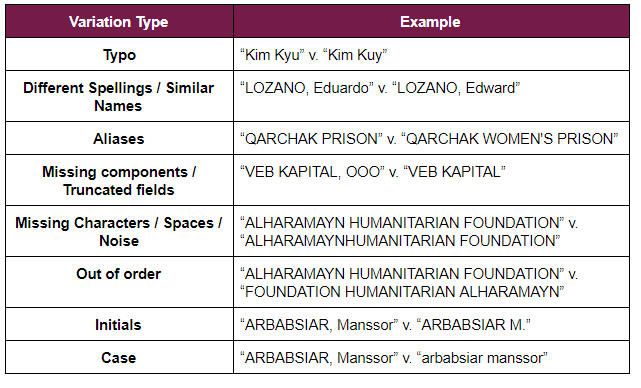
L'exemple ci-dessus est tiré de la liste SDN de l'OFAC en date du 06/12/2020
Les exemples ci-dessus doivent être utilisés comme référence, mais vous devez évaluer et prendre en compte tous les types de variations de noms, d'entités, de navires, d'avions, en rapport avec vos activités, et éviter de réutiliser les mêmes noms à l'infini dans vos tests pour éviter toute partialité. Les variations peuvent également être enchaînées (par exemple, une variation de cas et ensuite une variation hors service) et, selon la complexité, se voir attribuer une note de risque.
Les meilleures pratiques suggèrent que pour chaque score de risque et chaque type de variation, un grand nombre de variations générées de manière aléatoire soit utilisé, afin d'éviter tout biais introduit par l'utilisateur qui crée les cas de test.
Lors de l'examen des résultats, il convient de découper les données en utilisant différents tableaux de bord, notamment par score de risque et par type de variation. Il convient de noter que toutes les variations ne présentent pas le même risque. Par exemple, si un prénom et un nom de famille sont échangés, il faut considérer que le risque est plus élevé que si deux fautes de frappe sont appliquées à un nom.
Les institutions financières et les entreprises de services monétaires réglementées peuvent utiliser un large éventail de formats lorsqu'elles saisissent des informations, qui peuvent tous être mis à jour régulièrement, et présentent des spécificités qu'il convient de connaître lorsqu'on teste un système de filtrage des sanctions.
En effet, il est important de tester la capacité d'un système de filtrage des sanctions à capturer des noms avec et sans variation comme saisie de texte, mais aussi lorsque ces noms sont insérés dans des paiements ou des messages.
La première étape consisterait à tester différents noms placés dans tous ces formats, ainsi qu'à tester tous les champs pertinents pour le balayage, afin de s'assurer que les champs filtrés sont validés. Conformément aux recommandations Wolfsberg, les champs importants à filtrer sont les suivants :
1. Les parties impliquées dans une transaction, y compris le donneur d'ordre et le bénéficiaire, les agents, les intermédiaires et les institutions financières,
2. Les navires, y compris les numéros de l'Organisation maritime internationale (OMI), normalement dans les transactions liées au financement du commerce,
3. Le nom des banques, code d'identification de banque (BIC) et autres codes d'acheminement,
4. Des champs de texte libre, tels que les informations de référence du paiement ou l'objet déclaré du paiement dans le champ 72 d'un message SWIFT,
5. Le numéro international d'identification des valeurs mobilières (ISIN) ou d'autres identificateurs de produits pertinents pour le risque, y compris ceux qui se rapportent aux identifications des sanctions sectorielles 8 dans les transactions liées aux valeurs mobilières, et
6. La documentation sur le financement du commerce, y compris le :
En outre, les cas plus complexes devraient être réexaminés. Un exemple de marché connu serait celui des messages SWIFT, si l'entité "GASOLINERA Y SERVICIOS VILLABONITA, S.A. DE C.V." (49 caractères) devait apparaître dans un champ d'information de banque à banque (généralement le champ 72 dans un MT103), elle devrait être tronquée à la ligne suivante. En effet, les 49 caractères sont supérieurs à la limite de 35 caractères de chaque ligne dans un champ 72 dans SWIFT. En outre, après la première ligne, 2 caractères sont réservés au "//" marqué comme caractère de continuation. Le message SWIFT peut se présenter comme suit :
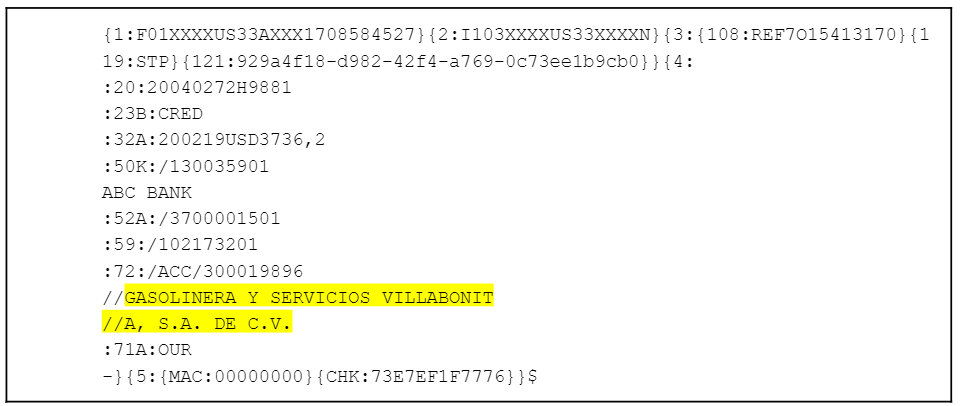
Les cas comportant de nombreux caractères doivent être examinés afin de s'assurer que les mots entiers ne sont pas séparés en lignes distinctes, comme dans le cas ci-dessus où "VILLABONITA" peut être scanné comme "VILLABONIT".
D'après notre expérience, il est crucial de tester consciencieusement ces formats car chacun a ses spécificités. Par exemple, dans le format Fedwire, la lettre "B" est insérée avant le code BIC sur le champ 5100, ce qui pourrait confondre certains systèmes lors du balayage des formats bruts Fedwire.
Les formats courants peuvent inclure SWIFT, Fedwire Funds Service (FED), Clearing House Interbank Payments System (CHIPS), SEPA, RTP, liste de noms de clients, XML, formats internes/propriétaires. La configuration de chaque champ/format doit être comprise dans la mesure où certains sont scannés comme un "nom complet" ou comme un texte libre.
Chacun de ces formats a une façon unique de structurer certaines données et informations applicables à la transaction et doit être correctement mis en correspondance avec les listes de sanctions.
Les contrôles des plateformes de sanctions doivent inclure une vérification de l'exhaustivité et de la mise à jour fréquente des listes de surveillance utilisées.
En effet, aux États-Unis, l'OFAC fonctionne selon le principe de la responsabilité objective, ce qui signifie que si un nom a été publié récemment, il est effectif immédiatement et doit être arrêté dès que la nouvelle liste est mise à jour.
La gestion des listes de sanctions est un sujet difficile, et il est important d'envisager l'automatisation du processus de mise à jour des listes de surveillance, en particulier si des tâches manuelles sont impliquées et si de multiples opérations doivent être effectuées pour rendre la liste disponible dans le système. L'utilisateur doit également vérifier la portée des listes surveillées, qui peuvent soit ne pas être suffisamment complètes, soit inclure des informations non pertinentes pour l'entreprise.
Enfin, aux États-Unis, il est courant d'inclure toutes les listes publiées par l'OFAC mais aussi la BIS et la BISN en fonction des opérations. D'autres listes typiques pourraient inclure des listes sanctionnées par Interpol, l'ONU et l'UE, ainsi que d'autres listes géographiques spécifiques et des listes de surveillance interne.
Comme vu dans le point n°3, tous les formats testés doivent être pris en compte tout en veillant à ce que seules les informations importantes soient examinées. Un processus d'examen continu devrait comprendre une justification et un test de l'examen de chaque format et de chaque domaine ainsi qu'une vérification des listes de surveillance appropriées.
À titre d'exemple, on constate souvent que les navires créent des résultats positifs pour les transactions de client à client qui ne seront pas pertinentes pour ce type de transaction. En outre, certains systèmes créent des résultats sur des alias faibles qui, la plupart du temps, n'apportent pas de valeur et créent de nombreux faux positifs.
En fonction de la plateforme de sanctions utilisée, les meilleures pratiques du secteur devraient être prises en considération, y compris le type de configuration, la portée du filtrage et le volume de faux positifs.
Souvent, les vendeurs organisent des groupes d'utilisateurs, y participer afin de comprendre les différentes versions du système et les meilleures pratiques pour le contrôle et le test des filtres.
Parallèlement, l'efficacité et l'efficience sont toutes deux importantes pour les tests et les vérifications. Lier ces deux aspects permet d'adopter une approche fondée sur les risques afin de parvenir au meilleur équilibre possible.
Un système générant un trop grand nombre de faux positifs non seulement épuisera les ressources opérationnelles, mais augmentera aussi considérablement le risque de passer à côté d'une entité sanctionnée, tandis qu'un système moins efficace manquera probablement des noms lorsqu'il sera légèrement modifié. Ces deux scénarios pourraient introduire un risque important de sanctions, ainsi que des amendes et un contrôle réglementaire.

Chez Sia Partners, nous avons développé la Sanctions Challenger Solution qui peut vous aider à automatiser le test de votre plateforme de filtre des sanctions. N'hésitez pas à nous contacter pour plus d'informations

